
Standardization | Normalization

I have always liked the power and magic that come from a computer and now I am a Web Developer and Data Scientist under construction.
I am also a coffee lover and enjoy lifting weights, music and plant-based food 🤓
Preprocessing Data
First things first! When we come across some dataset (raw data), it is recommended to follow these steps to understand and, if necessary, adjust your data for further analyses:
- Read Data
- Checking for missing values, categorical data, and outliers (and what to do with them)
- Apply preprocessing techniques as necessary
Some of the techniques are:
- Mean removal
- Standardization
- Normalization
- Binarization
- One Hot Encoding
- Label Encoding
In this post, I will cover the differences between Normalization and Standardization 🤓
Standardization vs Normalization
One of the things that we do is to understand what type of variables (which we call features, simplifying) our dataset have and in what scale/unit/range/magnitude they are presented.
If the features have a significant variability, we can use the concept of feature scaling as features with high magnitudes will weigh in a lot more in the distance calculations than features with low magnitudes. To address that, we need to bring them to similar magnitude levels by using methods such as standardization and normalization.
Normalization
This method scales the numeric variables in a certain range, usually from 0 to 1 or -1 to 1 when having negative values. It is also known as Min-Max scaling.
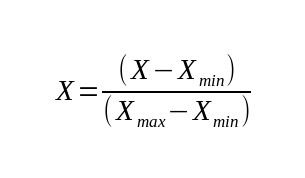
Through this method, we calculate the proportion of the distance between the value itself to the minimum value, and the distance of the maximum and minimum values (so we need to be careful regarding outliers).
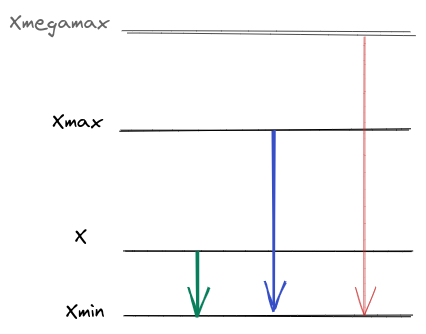 not nice to have outliers right?
not nice to have outliers right?
Standardization
This method uses the z-score formula to scale the values, resulting in a dataset of zero mean and unit variance.
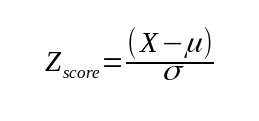
For a brief explanation, the z-score represents how many standard deviations a value is from the mean.
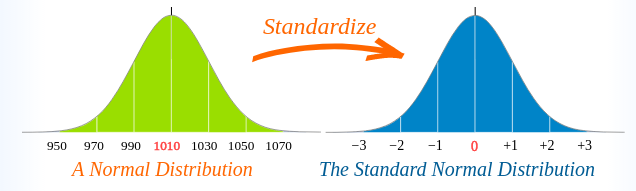 thanks to Math is Fun
thanks to Math is Fun



