




How I met Git
When first getting in touch with the software development world, I stumbled upon expressions such as "push to master", "merge this feature", "create a new branch", "commit this and that" ... and I was really lost. Like ... are you talking about trees? 🤔
Then a senior developer took his time to explain to me at least the basics about git, the main commands, and what is its purpose. Then later to this day, I started studying more and I must say ... git is really awesome (despite having some commands that are a little hard to understand sometimes).
What is Git
Before getting into the subject per se, let me just say how I admire Linus Torvalds (as a professional, not much his temper) for creating Linux and also creating the basics of Git in less than 2 days. TWO DAYS.
"It took about a day to get to be 'self-hosting' so that I could start committing things into git using git itself..." - Linus Torvalds for Linux.com
And about 10 days to get it really together.
"So I’d like to stress that while it really came together in just about ten days or so (at which point I did my first kernel commit using git)" - Linus Torvalds for Linux.com
And why the name Git? Well, let him tell it himself:
“The in-joke was that I name all my projects after myself, and this one was named ‘Git’. Git is British slang for ‘stupid person’,” Torvalds tells us. “There’s a made-up acronym for it, too—Global Information Tracker—but that’s really a ‘backronym’, [something] made up after the fact.” - Linus Torvalds for Welcome to The Jungle
Now let's get to the point
Git is a version control system that allows you to keep track of your projects and all its versions along with their changes. Most of the version control systems store information as a list of file-based changes. For instance, dropbox files are handled this way: it keeps the changes history of each file available so you can come back to an older version. If we see those changes as the difference between the current state of the file and the last state of the file, we can reference it as a delta Δ (same concept from calculus <3). And this is why this type of versioning is called delta-based.
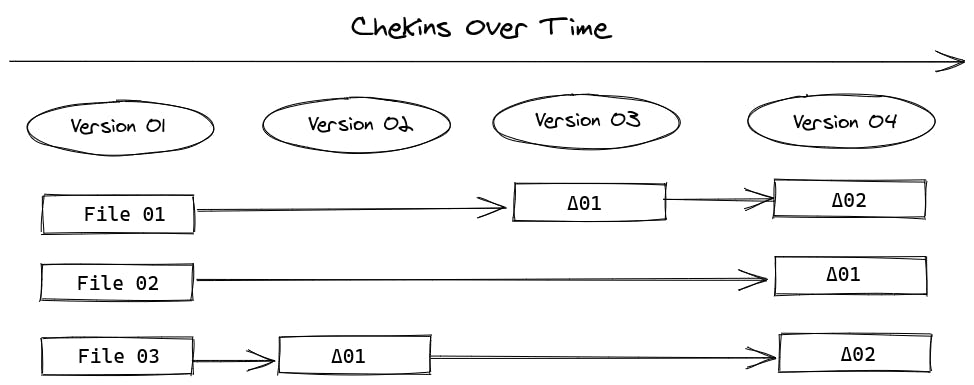 delta-based version control
delta-based version control
On the other hand, Git handles the files changes and data as snapshots over time. Every time you commit (save the desired state of your project), Git basically takes a picture of what all your files look like at that moment (the snapshot). To be efficient, if files have not changed, Git doesn’t store the file again, just a link to the previous identical file it has already stored. So, in the end, we have a stream of snapshots.
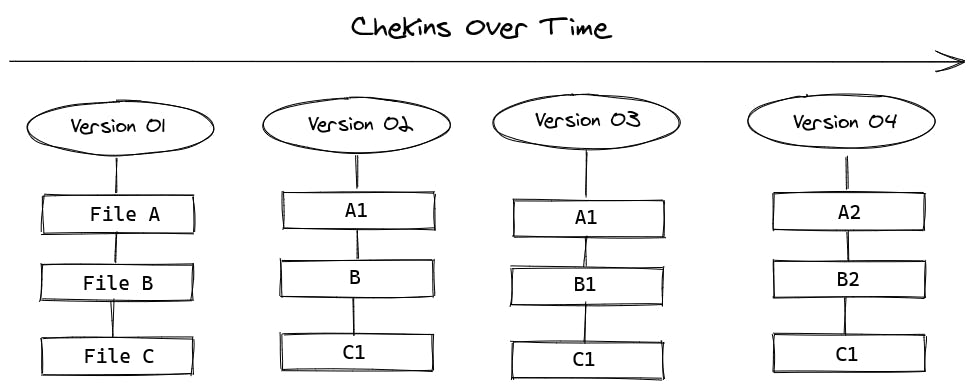 Git version control
Git version control
Git States
Before talking about Git states, it is important to note that we need to have Git inside our project, initiating a Git repository in it. To do that, just enter your project directory and type git init through the command line. It will create a git directory inside it called .git.

The most basic and fundamental Git concept is this one. Git has three main states in which a file can be found: modified, staged and committed. Bear in mind that you have to first say "hey, Git, track this file, please". If you do not add the file to be tracked, it will not be in any of these states as Git will not see it and therefore ignore it. When you add the file, it will automatically be staged.
Modified: it means that a tracked file is changed but you did not commit it yet (you did not save its current state)
Staged: when you have a modified file and then you think "Yes I am ready to save it as it is now!" you put it on the staging area. Then you mark it to go to your next commit (snapshot)
Committed: congrats, your modified file is now properly saved and stored to the database (and snapshotted 📸)
These three states are represented in three main places/areas/sections of your Git project: the working tree, the staging area, and the Git directory. Your file is in one of these sections depending on which state it resides.
Working Tree: single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify.
Staging Area: The staging area is the area that stores what will go into your next commit (it is actually a file in the Git directory). Git refers to it as the index.
Git Directory: The Git directory is where Git stores the metadata and object database for your project. It is the repository! Every time you initiate a git project, it creates a directory called
.git. And every time you clone a repository, this is what gets copied to your machine.
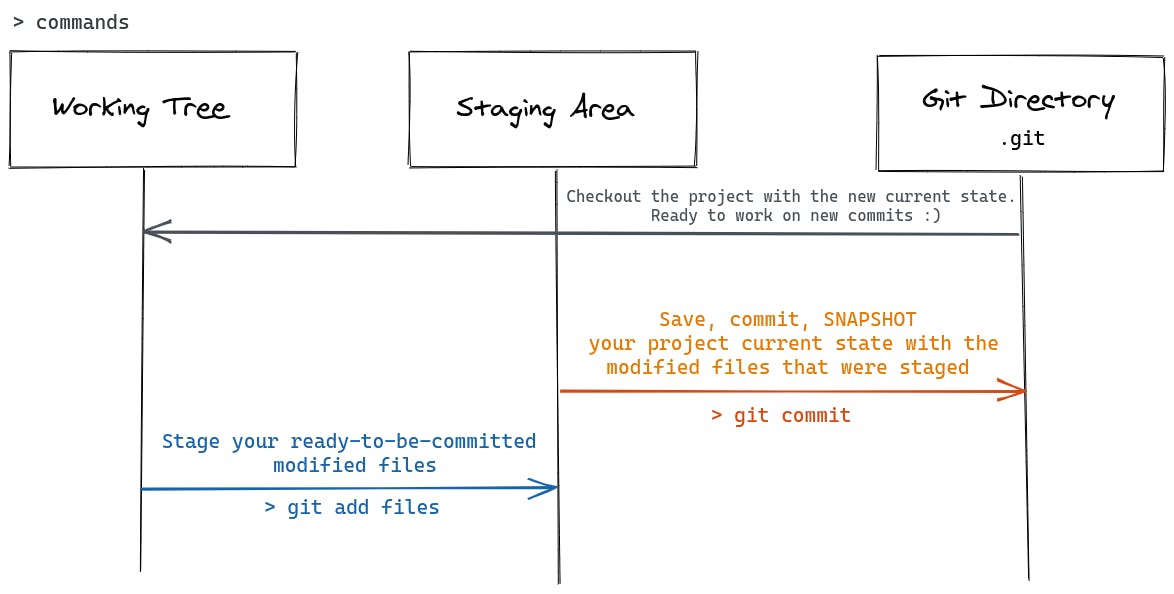 Git states
Git states
Simple example
Now, I will just walk through these concepts by showing a simple Git flow example.
- Initiate a git repository inside your project as shown above.
- Create a file. Change it until it is ready to be committed and ask Git to track it by using
git add file. It will put this file in the staging area.
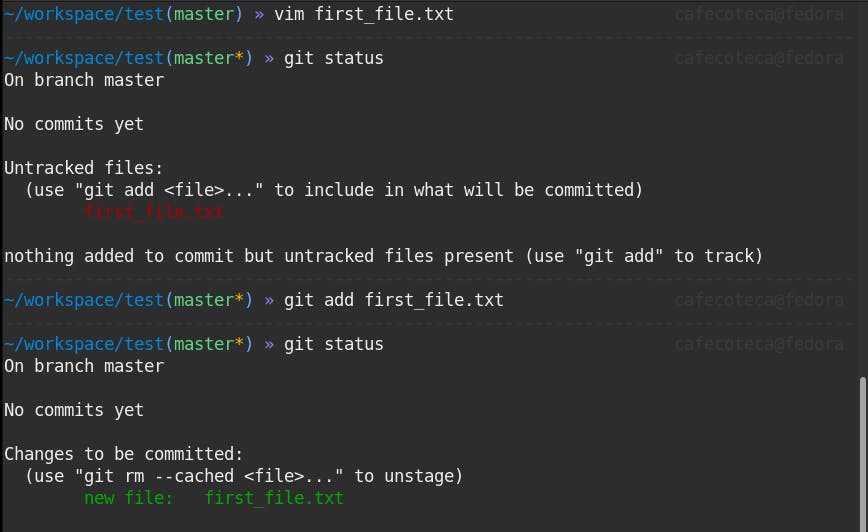
- Now I will do my first commit! Each commit should have a message stating what it is about and, if necessary, more detailed information. There are some best practices for commit messages which I will not cover here as it is not the scope of this article.
- So after committing, my staging area is clean, so is my working tree. And now I can start working on subsequent commits.
OK, so ... What is Github?
Simple and short: Github (and other services such as Gitlab) are just remote repositories in which you can keep your projects(public or private). Let's say an enhanced google drive for your Git projects 🤓. You can (and must) also check other people public repositories, follow them, check open source projects (and collaborate with them!). Companies also use these services to host their own source code.
I will cover more about it in later articles :)